CLOSE
testautomation testframeworks robotframework RF_testlibraries importing This is an older post, first published on the web site of the Agile Testers a couple of years ago. Since it is no longer available there and people are asking about it, I decided to re-publish it here.
This is the second post in a three-part series. The series will present a possible approach for overcoming certain problems that are inherent to the mechanism, which the Robot Framework implements to facilitate the sharing of resources.
Part one described the various types of resources that can be reused in your Robot Framework (RF) projects and the mechanism that enables this sharing. See here for part 1.
This second post will assume that you have read the first post and that you are thus familiar with the specific terminology surrounding RF resources. We will now take a closer look at the nature as well as the extent of the problems that are surrounding the reuse of RF artifacts.
The third (and final) post will then propose a simple, but effective and efficient, solution to these issues.
In a heterogeneous, complex technical environment many test libraries must typically be imported, since multiple interfaces need to be addressed when implementing test automation against the various front-end and back-end components. For instance, at the time of writing, I am working within a single environment where I need to automate against SOAP, REST/HTTP, DB2, JMS as well as a web-based graphical user interface.
In addition to the relevant interface driver libraries, a test project typically requires multiple convenience libraries (for the difference between interface driver libraries and convenience libraries, please see part 1 of this series). For any given test project, I will generally employ at least the following convenience libraries: Collections, OperatingSystem, String, and DateTime. Oftentimes also additional ones.
Even more convenience libraries are required when having to handle different in- and output formats, such as XML, JSON or others.
A product with even just a medium level of functional richness and/or complexity will require a lot of user keyword files and other types of user defined resources.
Generally, several abstraction layers of test functions, wrappers, object maps and other domain-specific resources will have to be implemented. Depending on the scope of your project (in terms of the test types to automate, the product components to automate, etc.) you will typically need dozens if not hundreds of functions.
Consequently, depending on the levels of modularization you apply to your solution’s design (usually mirroring the functional/logical breakdown of your SUT), you may end up with dozens of user keyword libraries and other user defined resources.
Generally, importing needs to be done at several layers/levels of your solution. Let’s have a look.
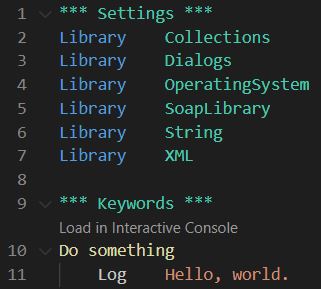
At the very beginning of your test project, you start out with just the libraries that are available to you through the standard test libraries (such as the XML library) and the installed external test libraries (such as the SoapLibrary).
Generally you will then proceed to create your own, user defined resources. For instance resource files containing user keywords, i.e. files that contain your own, domain-specific test functions.
The latter is accomplished by reusing the functions that are available in the (standard and external) test libraries. However, this requires each resource file to import every test library that is to be reused in that file. If you need to create a user keyword library containing functions that should get input XML from disk, call various SOAP services and validate the response XML, you will have to import at least three libraries within that resource file: SoapLibrary, XML library and OperatingSystem library. Moreover, in almost all cases of creating user keyword files you will employ several of the basic RF convenience libraries, such as the Collections and String libraries.
Accordingly, it is not uncommon to have more than five library import statements in a single resource file.
The more resource files you create, the more of these import statements you will end up with.
Identical to reusing a test library in a resource file, you will have to import any resource file that is, in turn, to be reused in the development of another resource file.
Typically, in the previous phase of test code development, you will have created a first, low-level layer of keyword libraries with technical activity level functions and other such resources. For instance libraries implementing the ‘glue-code’ (or ‘fixtures’) that connect to your domain code through some interface at the API or GUI level. Additionally you may also have created a set of resource files containing your own convenience functions (‘technical helper’ functions). And you will probably have created other types of resources as well, such as variable files.
After that first round of development, you will, in most cases, start to reuse the created resource files. Typically, you will create a layer of user keyword files that function at the workflow level and that will be reusing the keywords created at the technical activity level.
Finally, these workflow level keyword files may themselves be reused (and thus imported) by a final, thin layer of ‘wrapper’ keywords that implement (end-to-end) business flows.
Similar to what has been said in the previous section you can (and most probably will) end up with multiple import statements throughout your workflow level resource files as well as throughout the mentioned (end-to-end) business layer.
The number of statements may vary, depending on the functional (and technical) richness and complexity of your domain on the one hand and the specific design that you applied to your test automation solution on the other hand.
Typically though, that number will be sizable.
When you are done building your test automation solution (i.e. the domain-specific part of your test automation framework), you will then start to create/add your automated test designs.
Assuming the layering just outlined, you will use the domain-specific resource files that reside in the upper (workflow and business) layers to create your test designs. These keywords form the domain specific language in terms of which you can formulate your tests (please see this post).
Test cases in RF are implemented as test suite files (see part 1). To be able to use your domain-specific keywords in a test case, the containing test suite file will have to import the relevant user defined resource files. The exact number of import statements in a test suite file is therefore dependent on the number of user keyword libraries that are required to specify all of the test cases that are to be contained in that test suite.
Generally, there will be between two and (sometimes even up to) ten of these import statements in a test suite file.[1]
A test suite folder may feature its own set of import statements.
Specifically, it will require one or more of these statements when the need arises for suite-level setup and/or teardown routines. And/or in the case of having to specify default test setup/teardown routines.
These setup/teardown routines will, typically, be domain-specific. Therefore these routines will generally have been implemented through one or more user keywords, within one or more user keyword files. Consequently, all of the relevant resource files need to be imported within a logical test suite.
Just as is the case with programming languages such as Java or Python and as is the case with other proprietary scripting languages (such as that of FitNesse), there is no ‘inheritance’ of import statements within RF test code.
For instance, a test suite file does not ‘inherit’ any of the imports that its parent test suite folder may contain.
Notwithstanding, people starting out in test automation (especially those without any prior programming experience) are often quite surprised by this lack of inheritance. As a matter of fact, they often expect and assume inheritance and therefore see their code fail due to missing import statements.
However, the Robot Framework requires you to create an import statement for a resource (such as a test library or a user defined resource file) in every file (such as a test suite file or a user keyword file) that needs that resource.
So even if, for instance, you create an import statement for the XML test library at the level of a test suite folder, then each descendant of that folder (such as test suite sub-folders and a test suite file) still needs to have its own import statement for the XML library.
Depending on the factors described above (i.e. the technical and functional complexity and size of your domain, the scope of your automation project, your test strategy, etc.) you can end up with many import statements in each of a sizable set of files.
Given an average of six import statements (which is not uncommon in my experience), when you’d have merely thirty user keyword libraries, you’d end up with 180 import statements. Many of which will be duplicates.
In my experience, especially when working on an enterprise-level project, there are often not only more than 6 import statements per file (on average), but also many, many more user keyword libraries than those thirty. Thus, I regularly work on projects with many hundreds of import statements across the test code base.
It would not be too much of a stretch of the imagination, to assume that there may be projects out there that even have thousands of these statements.
Writing five different import statement fifty times effectively constitutes code duplication.
It can also be an effort in and of itself to maintain a large set of import statements and keep it efficient, consistent and relevant. For instance, if you wanted to change an import parameter, you would have to change it many times throughout the code base. Of course you can find and replace or even create a script to do the work for you. But that may always lead to errors/omissions and still means work to do.
Moreover, having to work with that many import statements can be confounding and can lead to mistakes.
Therefore, in the next (and last) post, I will propose a very simple, yet effective mechanism to reduce that work to an absolute minimum and, first and foremost, create simplicity.
[1] It is generally unnecessary to (directly) import test libraries into test suite files, since it is generally undesirable to insert technical low-level statements into your test designs. However, there are situations in which this may become necessary. In those cases you will end up with even more import statements in your test suite files. (back)
Comments
Please join the discussion: place a comment on this page.
The comment will be immediately visible in this comment section.
Please note a Github account is required to comment.